I put a witness on my AI. Devil's advocate killed three designs first.
Building sonmat · Part 5 of 5
The short version up front: sonmat v0.9 added an agent called sonmat-witness. It’s an external verifier that checks whether the main session’s output matches what the user actually asked for — without reading the main session’s reasoning.
That’s the clean design story. The real story happened while I was designing. In a single session I fell into the same trap three times, and each time a single round of /devil collapsed the assumption underneath the design. This post is about both halves.
Why a witness at all
sonmat started from a single rule: doubt. Whatever you wrote — AI or human — don’t take it at face value. Go back and look at it once more, suspiciously. That’s the discipline at the root of the whole project.
The place v0.9 ran into was where that rule doesn’t quite reach. Self-doubt doesn’t work on the self.
People know this one. You can’t proofread your own writing — your eyes skim past the typos because your brain knows what was meant. In an OR, the surgeon doesn’t read their own Time Out; another team member does. On a flight deck, when the captain calls “FLAPS — TWO,” the first officer doesn’t just respond “two.” They look at the lever and read the position back. Doubt has to come from outside the writer.
So if self-doubt doesn’t reach, you need a place outside to do the doubting from. That place is what witness fills.
The name I reached for first was actually hunsugun — a Korean word for the person who watches over your shoulder at a Go board and points out the move you missed. The role fit. But the word doesn’t carry into English cleanly, and the series runs in both languages, so I borrowed witness — broader, and the courtroom register turned out to fit the role just as well.
For the witness seat to actually do its job, two things have to be true.
- The verifier can’t see the executor’s reasoning. If it can, it inherits the executor’s rationalization and turns into a rubber stamp.
- The verifier’s input has to be the user’s actual words. Not the main session’s interpretation of “what the user wanted” — the raw turn the user typed.
Sonmat’s existing guard skill solved neither. guard runs inside the main session, sharing its full context. It’s fine for operational checks — running tests, blocking sensitive files, enforcing discipline conformance — but useless for “does this output match what was asked,” because there’s no structural isolation between checker and writer.
So I split witness out. What it actually looks like in code I’ll get to in a moment — but first, the design isn’t what made this release. What made it was what happened during the design.
Three reversals in one session
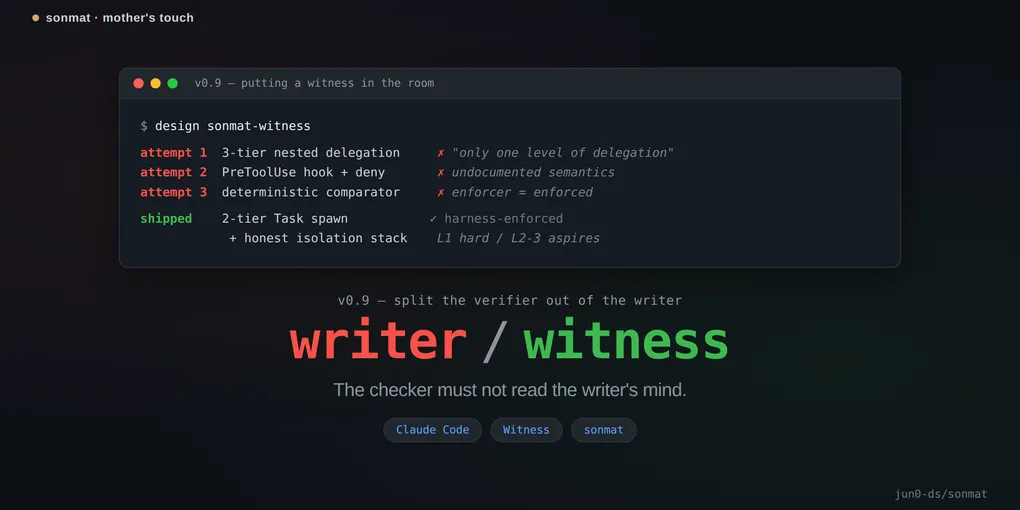
While building witness, I fell into the same kind of mistake three times in a row. Each time I’d accept a clever-sounding name or structure and start designing inside that frame. Each time /devil (sonmat’s devil’s-advocate skill, the subject of post 03) pulled out the load-bearing assumption underneath and showed me it didn’t hold. Three flips, same session.
Round 1: “the inverted three-tier architecture”
There was a line in sonmat’s memory from a month back:
“inverted three-tier design in progress.”
The main session as the human conversationalist, an orchestrator below it, workers below that. I’d been carrying this picture in my head for a month. When witness came up, it slotted naturally on top of the three tiers — the verifier sitting at the orchestrator layer, watching what the workers produced. Clean. Too clean, in retrospect — clean enough that I didn’t think to question it.
Last-pass check, ran a /devil CCT. CCT is the discovery step inside /devil: find the one load-bearing line of the claim first.
- Claim-crux: the architecture rests on the assumption that Claude Code supports nested subagent delegation.
- Counter-fit: the whole design was drawn before reading the platform docs. Zero evidence the assumption holds.
That line landed cold. A month-old picture, the whole thing hanging on a single sentence nobody had checked. So I read the docs. Claude Code’s multi-agent page:
“Only one level of delegation is supported: the coordinator can call other agents, but those agents cannot call agents of their own.”
Explicit ban. Three-tier was structurally impossible on the current harness. The instant “inverted three-tier” got written into a memory file a month earlier, every subsequent design conversation lived inside that frame — and nobody had asked whether the platform supported it.
Two-tier (witness-pair) is the actual ceiling, and I’d already been operating there the whole time. The third tier was vapor.
Round 2: “a PreToolUse hook spawns witness and denies the tool call”
Once the third tier retracted, I drew the next plan more carefully. Round 1 had just collapsed an hour earlier, so the cautious move was to verify as I went. Here’s the plan I came up with:
“In autoloop’s commit step, a
PreToolUsehook spawns witness as an agent-type hook. If witness returnsBLOCK, the hook denies the tool call.”
Tempting. Platform-level enforcement — no way for the main session to route around it. With the hook doing the gating, witness becomes a trustworthy chokepoint instead of leaning on discipline.
But — round 1 had also been tempting an hour ago, so the first thing on my mind this round was “is this pipeline actually in the docs?” Back to the official guides.
agent-type hooks exist. Documented.- But there are zero examples of
agenthooks fired onPreToolUsewith a verdict-based deny. Every documented example is onStop, used to verify tests pass. - The semantics of “hook spawns a subagent synchronously, waits, populates deny from the verdict” isn’t described anywhere.
CCT again.
- Claim-crux: that witness needs hook-layer enforcement to be trustworthy.
- Counter-fit: every other autoloop phase (
[Plan],[Define],[Execute],[Evaluate]) runs on discipline alone. Why is the witness gate special? - Cause-chain: “hook enforcement → trustworthy gating” only holds if the hook semantics actually exist. They don’t. The fallback is autoloop discipline — and autoloop already runs that way for everything else.
Flipped. Witness doesn’t need a hook. Spawn it inside [Judge] via the Task tool. Task + subagent_type is a well-documented primitive. Autoloop will run witness the same way it runs any other phase, and enforcement is autoloop discipline — the same thing already trusted for every other phase. No new guarantee; no pretending one exists.
Same shape as round 1, though. Attractive name, design inside the frame, no platform check, late collapse. The hour-younger me had repeated the hour-older me’s mistake almost exactly.
Round 3: turning the doubt on witness itself
By this point witness looked shippable. Execution isolated. Raw user turn as input. Citation rule in place. Two failures behind me — surely the third one wouldn’t show up.
But two failures sitting next to each other started bothering me. Both had the same shape: attractive name → design inside the frame → no platform check → collapse. “Inverted three-tier” had failed it. “PreToolUse hook deny” had failed it. So what about “witness” itself? Had I checked that name?
Last round, then. This time I aimed /devil at witness itself, with the strongest version of the claim I could put on paper:
“witness behaves like the deterministic comparator we designed — it compares, it doesn’t reason.”
What CCT picked out was different from rounds 1 and 2.
- Claim-crux: that writing “do not reason, compare” in the agent prompt makes the LLM actually behave that way.
- Counter-fit: witness isn’t an agent file. Witness is agent file + input + the model’s default tendencies, all stacked. The same class of LLM runs the main session and the witness. The failure mode that makes the main session rationalize during self-check could show up in witness too — and “we wrote a rule” is not structural protection against that.
- Cause-chain: “agent rules → strict comparator behavior” runs through instruction-following — which is the exact mechanism witness is supposed to be a check on. Circular.
Pause here. Rounds 1 and 2 had failed for external reasons — the platform didn’t support what I’d drawn. Searchable, factual problems with clear fixes. Round 3 was different. The problem was inside witness’s design: the enforcement mechanism for witness’s behavior is the same mechanism witness is supposed to be a check on. Self-referential. Strong-form claims don’t survive that.
But the weak form did.
The strong form — “witness is a deterministic comparator” — got weakened. The weak form — “witness is still better than main self-check” — held. The reason is that the layers separate cleanly.
Layer 1 — execution isolation (harness-enforced) ──── real structural guarantee
Layer 2 — spawn-prompt rules ──────────────────────── aspirational contract
Layer 3 — citation rule ───────────────────────────── aspirational contractLayer 1 the platform enforces. Even a sloppy witness can’t read the main session’s rationalization context — there’s no path to the confirmation-rubber-stamp failure mode, because the input it would rubber-stamp on isn’t reachable. That alone makes witness strictly better than self-check.
Layers 2 and 3 are prompt-level behavioral contracts. The runtime doesn’t enforce them. If witness decides internally “this finding is §2 but it feels weak, I’ll call it WARN” — nothing structural stops it.
That’s what v0.9.1 went in for. witness.md’s §Isolation stack now separates the three layers explicitly into enforced vs. aspirational, and it tells operators to manually sample verdicts in early use to check whether layers 2-3 actually hold up. Drift gets observed and fed back into the agent file. The scribe already logs witness verdicts to the journal, so the observation channel exists.
Witness isn’t a perfect verifier. It’s a structurally better one than self-check, and the difference is honestly bounded by layer 1. The rest is calibrated against reality as I use it.
What survived
The witness that came out of three breakages looks like this.
- A subagent spawned via the Task tool. The 3-tier picture from round 1 doesn’t exist; 2-tier is the harness ceiling, and that’s where witness sits.
- Run inside autoloop’s
[Judge]phase. Round 2’s hook-level enforcement isn’t real either, so witness runs on autoloop discipline — same way every other phase runs. - Fed only the raw user turn and the produced artifact. No main-session commentary, no chain-of-thought, no commit messages — and if any of those leak through, witness can’t cite them. That’s layer 1, harness-enforced.
- Required to cite. Every finding has to anchor on
user turn N: "exact quote"paired withfile:line. A finding without a citation gets discarded by construction. That’s layer 3 — a prompt-level contract, aspirational. - Source-based in its verdict.
BLOCKvsWARNisn’t a vibe call. The verdict is decided by which check produced the finding (§1 intent-scope, §2 intent-content, §3 framing-derived, §4 ground truth).§1/§2/§4→BLOCK,§3→WARN. The severity dial got removed entirely. - Three scopes. A single commit (
commit gate), all file changes in the session (session forest), and — when the user says something like “across the whole system” or “to every X” —principle coverage, where witness grep-checks that the principle landed everywhere it was supposed to. That last one is the sharpest mode.
Each broken design left a line behind.
A meta beat — discovery-led depth applied to itself
There’s a second thing in this release worth naming. I re-aligned the design of inspect, devil, and punch to all be discovery-led. (The old name was “cascade,” which never quite communicated the direction.)
The core idea is simple: depth comes after discovery. You don’t decide how deep to go before you have a target — something surfaces, and the surface decides the depth. Chess players run CCT — Checks, Captures, Threats — before calculating any long variation. Surgical teams run the Time Out before incision. Aviation challenge-and-response works because PM doesn’t take PF’s word — PM looks at the switch. Five different verification traditions, same structural move.
I borrowed CCT for /devil too — Claim-crux, Counter-fit, Cause-chain. Instead of attacking a claim in parallel along four axes, you find the one load-bearing assumption first, classify whether it sits on Evidence, Logic, or Alternatives, and pour depth into that one axis. The other axes get a light pass.
The three /devil rounds today were the first live test of this rewrite. If I’d run them as parallel attacks — is witness good? is the three-tier good? is the hook good? — the conclusions wouldn’t have landed this cleanly. CCT picked a single load-bearing assumption every time, and pulling on that one thread collapsed the whole structure. The principle worked on the person who designed it.
What v0.9 actually shipped
- sonmat-witness — external intent-artifact comparator. Three scope scales (commit / session forest / principle coverage). Source-based verdict (
BLOCK/WARN/PASS/INSUFFICIENT_GROUND_TRUTH). - guard / scribe split — guard does pure verification (operational checks + discovery), scribe handles after-the-fact persistence (project rules, novel-trap memory, journal, bridge notes, witness verdict logs).
- discovery-led realignment —
inspectis trigger-reactive depth,deviluses CCT to find load-bearing and attack asymmetrically,punchtreats the user’s invocation itself as the discovery that opens the mode. /punchrefactor-residue check — finds stale references that survived a structural removal or rename. Seven patterns: section / function / file / terminology / example / enum / template.- Honest framing of the isolation stack — layer 1 (harness-enforced) vs. layer 2-3 (aspirational). No strong-form packaging; the doc names which parts are structural and which parts are hope.
- Feature request doc — four platform primitives that would make witness stronger but currently don’t exist (input-channel restriction, nested delegation, session layer, documented hook patterns). Filed under
docs/feature-requests/claude-code-isolation.md.
v0.9.0 shipped the agent + restructure. v0.9.1 was the honest-framing pass.
The one-line lesson
Before you design on top of a clever-sounding name, verify the platform actually supports it. “Inverted three-tier,” “PreToolUse agent hook + deny,” “deterministic comparator” — all three sounded shippable. All three either didn’t hold or held only weakly when something pulled on the load-bearing piece. CCT picked the right thread every time.
The bigger point: writing a principle into the docs is not the same as the principle holding under pressure. You have to keep an eye on how the principle applies to the person writing it. Today was the first chapter of that observation.
Release notes: v0.9.0, v0.9.1 Repo: https://github.com/jun0-ds/sonmat
Part of the series Building sonmat. Previous: GPT-4 said strawberry has two R’s. The word has three. (한글판은 /ko/blog/building-sonmat/05-witness-v0-9/)