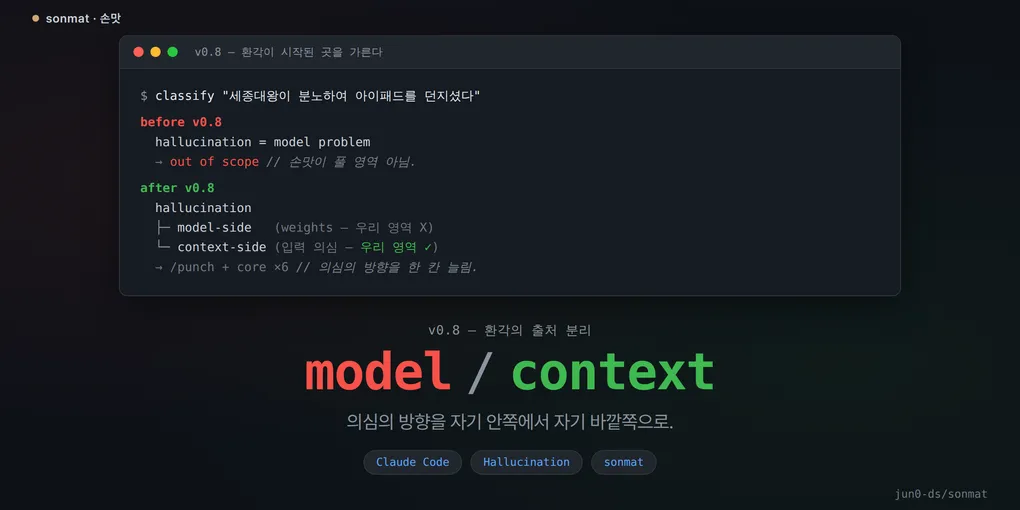
“세종대왕이 분노하여 아이패드를 던지셨다”
ChatGPT 초창기에 한국 LLM 커뮤니티를 돌던 농담이다. 한글 창제 일화를 묻자 모델이 천연덕스럽게 던진 답. 학습 분포 어딘가에서 그럴듯한 단어들이 통계적으로 엉겨붙은 결과다. 환각이라는 말을 들으면 보통 이런 그림이 떠오른다.
정확히 말하면 모델은 그 답을 진짜로 던졌다. 다만 손맛 v0.8.0(2026-04-11)이 다룬 환각은 이게 아니었다.
환각 7%를 들여다봤더니
발단은 한 24B 모델로 돌린 2,700회 위키 QA 테스트였다. 환각률 7%. 숫자만 보면 “역시 LLM은 환각이 있군” 하고 넘어갈 만한 수치다. 그런데 막상 7%에 잡힌 응답을 하나씩 까보니 그림이 달랐다.
세종대왕-아이패드 같은 진짜 환각, 그러니까 모델이 학습 분포에 없는 걸 만들어낸 케이스는 의외로 적었다. 더 많이 잡힌 건 이런 거였다.
사용자가 “시설관리는 A 테이블에 있어”라고 말했다. 사실은 B 테이블에 있었다. 모델은 충실하게 A 테이블을 뒤졌다. 거기 없으니 혼란스러워했고, 결국 그럴듯한 추측을 짜냈다. 이 응답이 환각률 7%에 잡혔다.
이게 환각인가? 사용자 입장에선 그렇다. 틀린 답이 나왔으니까. 그런데 같은 상황을 사람한테 시켜도 결과는 똑같다. 잘못된 매뉴얼을 쥔 인턴이 시설관리 담당을 찾으러 나서면, 결국 헛도는 답을 들고 돌아온다. 모델 문제가 아니라 입력 문제다.
두 출처가 섞여 있었다
여기서 한 칸 갈라줘야 한다. 사용자가 경험하는 환각은 하나의 사건이지만, 그 사건이 어디서 시작됐는지는 두 갈래다.
| 출처 | 어디서 발생 | 처방 |
|---|---|---|
| 모델 측 | weights 안에서 그럴듯한 조합이 만들어짐 (세종대왕-아이패드 류) | 모델 연구자 영역. weights를 바꿔야 줄어듦 |
| 맥락 측 | 받은 입력 자체가 틀렸고, 모델이 충실히 따라감 | 입력을 의심하는 구조. 시스템 설계자 영역 |
학계 분류도 일치하지 않는다. faithfulness(입력에 충실한가) 기준으로 보면 맥락 측 케이스는 “충실하니까 환각 아님”이고, factuality(사실에 부합하는가) 기준으로 보면 “사실과 어긋났으니까 환각 맞음”이다. NLG 환각 서베이(Ji et al. 2023)의 intrinsic/extrinsic 분류로 보면 어디에도 깔끔하게 안 들어맞는다. 입력엔 충실하면서 사실엔 어긋난 케이스니까.
학계가 합의를 못 보는 이유는 단순하다. 사용자 시점에선 둘 다 “AI가 틀린 답을 줬다”로 동일하다. 다만 도구를 짜는 입장에선 다르다. 출처가 갈리면 처방도 갈린다. 모델 측은 우리가 못 건드린다. 맥락 측은 건드릴 수 있다.
v0.8은 건드릴 수 있는 쪽만 다뤘다.
그 분리가 보이기 전까지
이렇게 정리하고 보면 갈라보는 게 자명한 것 같지만, 사실 나는 한참 못 보고 있었다. “환각 = 모델 문제”라는 한 줄을 그냥 받아들이고 있었다. 손맛에 의심 도구를 아무리 보태봤자 weights에서 만들어지는 그 통계적 조합을 무슨 수로 줄이겠나 — 그래서 환각은 손맛이 풀 영역이 아니라고 한쪽에 치워두고 있었다.
7% 분석을 본 게 깨는 계기였다. frame이 틀렸던 게 아니라 scope를 너무 좁게 잡고 있었던 거다. 받은 frame을 의심하라는 도구를 만들면서, 정작 본인이 받은 frame은 의심도 없이 그대로 밟고 서 있었다. 부끄러운 자리지만, v0.8의 진짜 발단은 거기였다.
이후 두 변화는 그 깨달음을 디시플린(추론 규칙)과 스킬(액션 도구) 양쪽에 동시에 박은 거다.
core 6곳에 박힌 한 줄
먼저 디시플린부터 손봤다. 손맛의 discipline/core.md는 “Claude가 어떻게 사고해야 하는가”를 규정하는 짧은 문서인데, v0.8 전까지 의심의 방향이 거의 다 자기 자신 쪽이었다. “내 가정이 진짜 확실한가?”, “결론으로 점프 안 했나?” 같은 질문들.
v0.8에서 의심의 방향을 한 칸 더 늘렸다. 자기 추론만이 아니라 받은 맥락 자체도 의심하라고. 같은 한 줄을 core 안 6곳에 끼워 넣었다.
받은 맥락은 세 가지 방식으로 망가져 들어온다.
- incomplete — 빠뜨리고 안 말한 부분
- imprecise — 대충 말한 부분
- incorrect — 틀리게 말한 부분
셋이 같이 굴러간다. 하나만 의심하면 다른 둘이 빠져나간다. 가령 One-beat pause는 v0.8에서 이렇게 바뀌었다.
### One-beat pause
Before agreeing with anything — is there something worth doubting here?
If the question even crosses your mind, that's the signal. Check before you nod.
+This includes the context itself — it may be incomplete (left unsaid),
+imprecise (said loosely), or incorrect (said wrong).
+All three coexist; don't fixate on one.같은 패턴이 Strip to essentials, Predict before acting, Ground it, Pace it, Weight it에도 들어갔다. 특히 Weight it에는 신뢰도의 출처를 쪼개라는 한 줄이 같이 박혔다. verified fact / user statement / inference / guess 넷 중 어느 거냐. “이건 80% 확신”이 아니라 “이건 사용자 진술 기반 80%고, 검증된 사실은 아님”으로 층을 나누라는 얘기다.
한 줄짜리 추가들이 모인 거라 작아 보이지만, 실제로는 손맛이 다루는 의심의 영역을 자기 안쪽에서 자기 바깥쪽까지 한 칸 늘린 결정이었다. 도구가 자기 추론만 의심하고 있으면, 사용자가 “A 테이블에 있어”라고 잘못 말한 순간부터 통째로 끌려간다.
같은 깨달음의 다른 얼굴 — /punch
core를 손본 게 한쪽 얼굴이고, 같은 릴리스에 들어간 /punch 스킬이 다른 얼굴이다.
깔린 배경은 커뮤니케이션 에러 연구의 양적 결과다. 항공 CRM(Helmreich), 수술실(Lingard 2004), SW공학(Boehm/Firesmith). 분야가 다 다른데 비율이 묘하게 비슷하다.
| 에러 유형 | 비율 |
|---|---|
| 생략 (omission) | 40–55% |
| 모호함 (imprecision) | 20–25% |
| 사실 오류 (incorrect) | 10–15% |
| 맥락/타이밍 오류 | 10–20% |
미리 짚어둔다. 이건 사람-사람 커뮤니케이션의 분포다. LLM에 같은 비율이 그대로 들어맞는다는 직접 증거는 없다. 검증된 정량 결과가 아니라 옆 동네에서 빌려온 가정이다. 다만 omission이 incorrect보다 훨씬 흔하다는 일반 패턴은 LLM 쪽에서도 정성적으로 비슷해 보였고, punch의 설계 가이드로는 그 정도면 충분했다. 모델이 정면으로 틀린 사실을 만들어내는 것보다, 사용자가 안 말한 부분을 모델이 알아서 채워 넣다가 어긋나는 경우가 더 많다.
그러면 가장 큰 ROI는 빠진 걸 찾는 데 있다. 그런데 기존 손맛 스킬은 이걸 못 잡고 있었다.
/guard— “이 작업이 안전한가?”/inspect— “어디가 부서질 수 있나?”/devil— “이 추론이 타당한가?”
셋 다 “지금 있는 것”을 검사한다. “있어야 하는데 빠진 게 있는가”는 아무도 안 묻고 있었다. 그 빈자리를 채우는 게 punch다.
guard는 “is this safe?” inspect는 “what could break?” devil은 “is this reasoning sound?” punch는 “is anything missing?”
이름은 건축 현장의 punch list에서 빌려왔다. 시공이 끝난 건물을 시공자와 같이 한 바퀴 돌면서 “이 콘센트는 도면에 있었는데 없네”, “이 문은 안 닫히네”, “이 화장실 자리에 화장실이 없네” 같은 누락을 줄줄이 적어 넘기는, 그 리스트.
punch가 두 다리로 서는 이유
메서드는 단순하다. 재구성 + 도메인 체크리스트, 두 다리.
1. 재구성 (Reconstruct)
코드만 봐서는 의도를 다 알 수 없다. 사용자 머릿속에는 있었지만 끝까지 코드로 안 내려온 부분이 있고, omission은 거기서 가장 많이 새 나간다. 그래서 punch는 일방 분석이 아니라 대화로 시작한다.
[punch] 구현을 보고 짐작한 의도:
유저 스토리: [...]
계약: [...]
제약: [...]
불확실: [짐작 안 되는 것 — 의견 필요]
빠지거나 다르거나 잘못된 게 있나요?이 시점의 punch 출력은 결론이 아니라 체크포인트다. 사용자가 “아 이거 빠뜨렸네”, “이건 의도랑 다른데” 하고 짚어주는 라운드가 진짜 가치 있는 부분. 항공 challenge-and-response, 수술실 Time Out, 군사 brief-back. 검증 전통들이 공통으로 보여주는 패턴이 그것이다. 만든 사람과 다른 사람이, 만든 직후에, 한 번 맞춰본다.
2. 도메인 체크리스트
재구성만으론 부족하다. 사용자 본인도 까먹은 부분은 재구성에서 영영 안 나온다. 아까 그 “화장실 자리에 화장실이 없는” 케이스. 그래서 두 번째 다리로 도메인 체크리스트를 얹는다.
| 도메인 | 핵심 항목 |
|---|---|
| Web app | Auth/세션, 입력 검증, 에러 페이지, 로딩 상태, 반응형, 접근성, CORS, rate limit |
| API | 버저닝, 에러 포맷, 인증, pagination, timeout, idempotency, 문서 |
| 데이터 파이프라인 | 스키마 검증, null/empty, dedup, retry, 모니터링, backfill |
| CLI | help, exit code, stdin/stdout, 에러 메시지, config, —dry-run |
| ML/AI | baseline, eval, data leakage, latency, 실패 fallback |
체크리스트가 모든 걸 잡지는 못한다. 이 프로젝트에만 있는 고유 요구는 거기 없다. 다만 재구성이 잡는 영역과 체크리스트가 잡는 영역이 직교한다. 한쪽이 “이 프로젝트에서만 의도된 것”, 다른 쪽이 “이런 도메인이면 보통 있어야 하는 것”. 한 다리만 켜두면 다른 한쪽이 새 나가는 구조라, 굳이 두 다리로 세워뒀다.
거기까지가 한계다
이 frame이 어디까지 단단하고 어디부터 희망이 섞여 있는지, 솔직하게 갈라두자.
-
진짜 환각은 그대로 남아 있다. 세종대왕-아이패드 류는 v0.8로 안 줄어든다. 모델 측 출처는 weights를 갈아야 빠지고, 그쪽은 모델 연구자 영역이다. 손맛은 거기 손 못 댄다.
-
7% 분석은 한 사람이 한 모델로 돌린 한 번의 테스트다. 24B, 2,700회 QA, 위키 도메인. 다른 모델, 다른 도메인, 다른 프롬프트에서 같은 분포가 다시 나온다는 보장은 없다.
-
에러 비율 표는 사람-사람 커뮤니케이션 연구에서 가져왔다. 항공 CRM, 수술실 관찰, SW공학 회고. LLM 환각의 출처 분포도 같은 비율이라는 직접 증거는 아니다. 정성적으로 비슷해 보인다, 정직하게 말할 수 있는 건 거기까지다.
-
출처가 깔끔하게 안 갈리는 사례도 있다. 사용자가 어정쩡하게 말하고, 모델이 그 어정쩡한 부분을 자기 학습 분포에서 적당히 채우는 케이스. 맥락 측과 모델 측이 한 응답 안에서 섞인다. 이런 건 우리 frame에서 절반만 잡힌다.
이 한계 위에서 v0.8이 결국 뭘 한 거냐, 한 문장으로 줄이면 이렇다.
교훈 한 줄
환각이라는 한 단어에 묶여 있던 사건을 출처별로 갈라놓은 것, 그게 v0.8이다. 한쪽 출처(모델 측)는 우리가 못 푼다. 다른 쪽(맥락 측)은 풀 수 있다. 푸는 방향이 두 갈래로 떨어졌다. core 안 6곳에 의심의 방향을 입력 맥락 쪽까지 늘리는 한 줄을 박았고, 같은 깨달음의 다른 얼굴로 빠진 것을 찾는 도구 /punch를 새로 깎았다.
디시플린과 스킬 양쪽에 같은 인사이트가 동시에 박힌 건 우연이 아니다. 한 발견의 두 얼굴이었으니까. 환각의 본질을 푼 건 아니다. 환각이라고 잘못 묶여 있던 다른 사건의 본질을 짚어냈을 뿐이다.
의심의 방향을 자기 안쪽에서 자기 바깥쪽으로 한 칸 옮긴 것. 손맛은 거기서 한 단계 나아갔다.
릴리스 노트: v0.8.0 리포: https://github.com/jun0-ds/sonmat
시리즈 손맛 (sonmat) 만들기 네 번째 글. 이전 글: 내 의심 도구가 너무 잘 작동했다. 그게 문제였다.